

Fehlerhafte Daten sind teuer. Und auch problematisch. Wir erklären, was Datenqualität ist und wie gut Ihre Daten sein müssen.
Wer kennt es nicht?
Name: Am Mustergraben 8
Telefonnummer: 000-0000-000
Kaufdatum: 32/32/32
...
Die Liste von fehlerhaften Daten ist lang und die Probleme und Kosten schlechter Datenqualität alltägliche Realität in der deutschen Unternehmenslandschaft: Vom Nichterreichen der Kundschaft über die falsche Ansprache in einem Newsletter bis hin zur falschen Rechnungsstellung – um nur einige Beispiele zu nennen. Getreu dem "Garbage in, Garbage out”-Prinzip führen schlechte Daten zu schlechten Entscheidungen. Experian Marketing Services fand in diesem Zuge Folgendes heraus: 73% der deutschen Unternehmen denken, dass ungenaue Daten sie daran hindern, eine herausragende Customer Experience zu bieten.
Eine gute Datenqualität ist damit entscheidend für das tagtägliche Handeln eines Unternehmens und vor allem ein maßgeblicher Erfolgsfaktor – nicht nur für Data Science Projekte. Doch was bedeutet Datenqualität überhaupt, was sind Datenqualitätskriterien, wie gut müssen Daten für ein Data Science Projekt sein und wie können Unternehmen Datenqualität messen? Diese Fragen klären wir in diesem Artikel.
Was ist Datenqualität und warum ist Datenqualität so wichtig?
Datenqualität Definition: Generell bezieht sich Datenqualität (Eng. Data Quality) darauf, wie genau, vollständig, konsistent und aktuell Daten sind. Hohe Datenqualität bedeutet, dass die Daten frei von Fehlern, Inkonsistenzen und veralteten Informationen sind. Eine niedrige Datenqualität führt zu fehlerhaften Erkenntnissen und schlechten Entscheidungen, die auf ungenauen oder unvollständigen Daten basieren.
Datenqualität beschreibt jedoch auch, wie gut sich Datenbestände für vorgesehene Anwendungen eignen. Man spricht daher in diesem Kontext auch von der „Fitness for Use“ – also die Zweckeignung der Daten. Die Qualität von Daten ist damit sehr kontextabhängig. Denn während die Datenqualität für einen bestimmten Anwendungsfall ausreichend sein kann, könnte sie dennoch für einen anderen Fall ungenügend sein.
Warum ist sie so wichtig? Datenqualität ist die Grundlage für Unternehmen, um vertrauenswürdige Daten für Analysen, Geschäftsprozesse und Entscheidungsfindungen zu haben. In einem Data Science Projekt basiert alles auf der Ressource Daten. Im Projekt werden Daten aus verschiedenen Quellen zusammengeführt und dann analysiert. Diese Daten dienen somit als Input für jegliches Analysemodell. Ein ausgefeilter Algorithmus bringt also nichts, wenn die Qualität der Daten schlecht ist. Auch wenn ein Data Science Projekt aus vielerlei Gründen scheitern kann, steht und fällt der Projekterfolg primär mit der Qualität der verfügbaren Daten. Lesen Sie dazu auch unseren Beitrag “Wie man Data Science Projekte meistert”.
Sie sind gut beraten, in Maßnahmen zu investieren, die eine hohe Qualität Ihrer Daten sicherstellen. Zum einen maßgeblich für den Projekterfolg, aber auch darüber hinaus. Denn durch mangelnde Datenqualität können erhebliche (Folge-)Kosten für ein Unternehmen entstehen. Schauen wir uns das mal an.
Schlechte Datenqualität kostet mehrfach
Schlechte Datenqualität hat einen Namen: Dirty Data. Diese Daten sind geprägt von niedrigen Werten, wenn es um Konsistenz, Vollständigkeit, Korrektheit und Aktualität geht. Hier einige Fakten, wie sich diese Umstände monetär auswirken:
- Gartner schätzt den durchschnittlichen Umsatzverlust von Unternehmen durch fehlerhafte Daten auf bis zu 15 Millionen US-Dollar (Gartner’s Data Quality Market Studie). Oder anders ausgedrückt: Die Kosten schlechter Datenqualität belaufen sich auf 15% bis 25% Ihres Umsatzes (veröffentlichte Studie im MIT Sloan Management Review).
- 50 % des IT Budgets werden für die Wiederaufbereitung von Daten ausgegeben (Zoominfo).
- Sobald eine Datenreihe aufgenommen wurde, kostet es 1 Dollar diese zu verifizieren, 10 Dollar diese zu bereinigen und 100 Dollar, wenn diese fehlerhaft bleibt (Abb. 1).
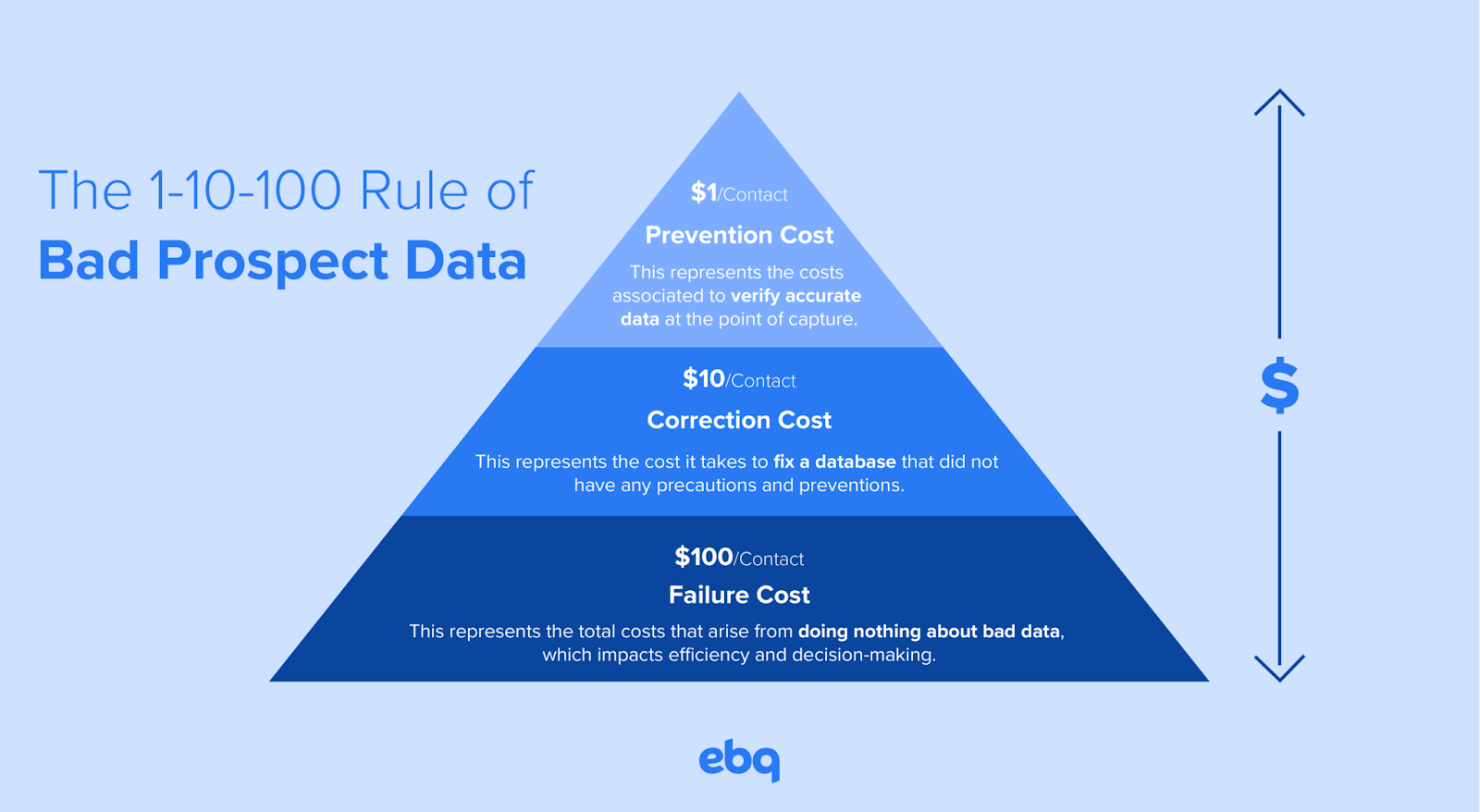
(Abb. 1: The 1-10-100 Rule of Bad Prospect Data, ebq)
Darüber hinaus verursacht eine schlechte Datenqualität weitaus weitreichendere Konsequenzen als finanzielle Verluste. Dazu gehören Auswirkungen auf das Vertrauen der Mitarbeitenden in Entscheidungen, die Zufriedenheit der Kund:innen und Markenimage, Produktivitätseinbußen (durch z. B. zusätzlich benötigte Zeit zur Datenaufbereitung), Compliance Probleme, negative Folgen für Vertrieb- und Marketingteams und verlangsamte Verkaufszyklen und mehr. Heutzutage läuft jedes Unternehmen auf Grundlage von Daten – schaffen Sie ein sicheres Fundament. Und das bedeutet ein sauberes Datenqualitätsmanagement.
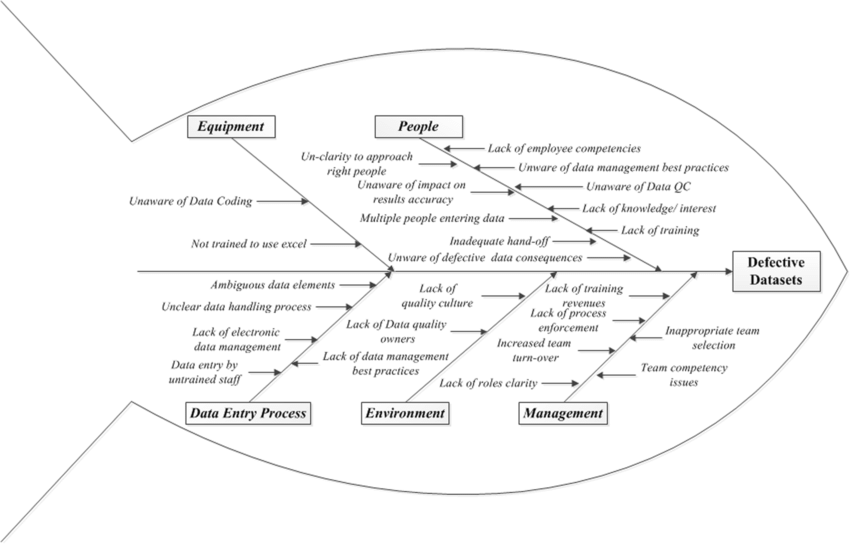
(Abb. 2: Ursachenanalyse von Datenfehlern, Researchgate)
Was sind die Quellen schlechter Datenqualität?
Die Quellen schlechter Datenqualität können sehr vielseitig sein, wie Abb. 2 verdeutlicht. Allem voran steht zumeist jedoch die manuelle menschliche Dateneingabe (s. Abb. 3).
1. Manuelle Dateneingabe: Beim manuellen Erfassen von Daten durch Menschen kommt es leicht zu Flüchtigkeitsfehlern, Tippfehlern oder Inkonsistenzen. Selbst kleine Abweichungen können sich in den Datenbeständen akkumulieren und zu massiven Qualitätsproblemen führen. Dies ist der Hauptgrund für eine niedrige Datenqualität.
2. Veraltete Daten: Wenn Datensätze nicht regelmäßig aktualisiert und bereinigt werden, verlieren sie mit der Zeit an Genauigkeit und Relevanz. Veraltete Daten führen zu verzerrten Analysen und falschen Geschäftsentscheidungen.
3. Datensilos: Isolierte Datenbestände in unterschiedlichen Systemen erschweren die Datenkonsistenz und -integration enorm. Redundante, sich widersprechende Daten sind die Folge.
4. Fehlende Datenverwaltung: Ohne klare Prozesse, Metriken, Rollen und Verantwortlichkeiten für Datenqualitätsmanagement bleibt dieser kritische Bereich unkoordiniert und vernachlässigt. Öffentliche Stellen oder Behörden müssen im Zuge der DSGVO immer einen Data Protection Officer (DPO) benennen. Jedoch kann die Benennung eines DPOs auch für nicht-verpflichtete Firmen sinnvoll sein, um eine angemessene Datenqualität sicherzustellen.
5. Komplexe Datenquellen: Je mehr heterogene Datenquellen von unterschiedlicher Struktur und Herkunft integriert werden müssen, desto aufwändiger wird die Datenbereinigung und -harmonisierung.
6. Systemfehler: Selbst kleine Fehler oder Bugs in Datenbanken, Schnittstellen oder ETL-Prozessen können im großen Maßstab zu erheblichen Datenfehlern führen.
7. Mangelnde Qualifikation der Belegschaft: Ohne Schulungen und Sensibilisierung der Mitarbeitenden für Datenqualität bleibt dieses Thema unterschätzt und anfällig für menschliche Fehler. Daten müssen Teil ihrer Unternehmenskultur werden.
Insgesamt müssen Organisationen Datenqualität strategisch angehen. Das bedeutet kontinuierliches Monitoring, automatisierte Regeln und eine aufgeklärte Datenkultur.
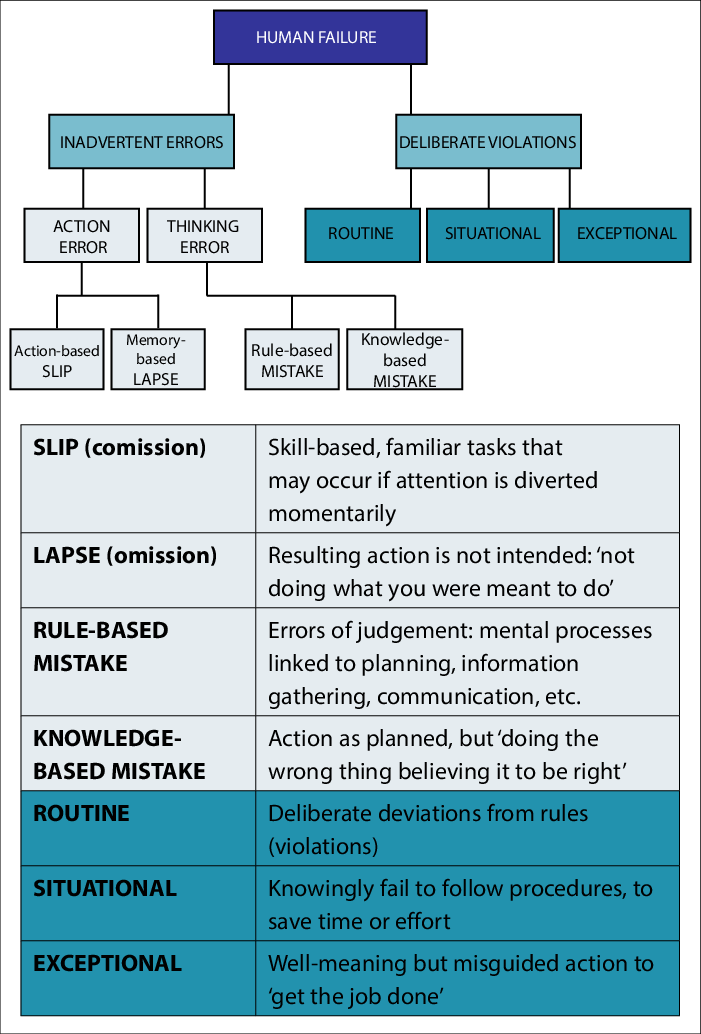
(Abb. 3: Menschliche Fehlerarten, Researchgate)
Wie wird die Datenqualität gemessen?
In der Praxis gibt es eine Vielzahl an Kriterien, mit deren Hilfe sich die Qualität von Daten bewerten lässt. Zu den gängigsten Bewertungskriterien gehören unter anderem die folgenden:
- Korrektheit: Stimmen die Daten sachlich mit der Realität überein?
- Konsistenz: Stimmen die Daten aus unterschiedlichen Systemen miteinander überein?
- Vollständigkeit: Enthält der Datensatz alle notwendigen Attribute und Werte?
- Einheitlichkeit: Liegen die Daten im passenden und im selben Format vor?
- Redundanzfreiheit: Kommen innerhalb der Datensätze keine Dubletten vor?
- Genauigkeit: Liegen die Daten in ausreichender Zahl genau vor?
- Aktualität: Spiegeln die Daten den aktuellen Zustand wider?
- Verständlichkeit: Ist jeder Datensatz eindeutig interpretierbar?
- Zuverlässigkeit: Ist die Entstehung der Daten nachvollziehbar?
- Relevanz: Erfüllen die Daten den jeweiligen Informationsbedarf?
- Verfügbarkeit: Sind die Daten für berechtigte Nutzer zugänglich?
Die Kriterien Korrektheit, Vollständigkeit, Einheitlichkeit, Genauigkeit und Redundanzfreiheit beziehen sich im Allgemeinen auf den Inhalt und die Struktur der Daten. Sie decken eine Vielzahl der Fehlerquellen ab, die am häufigsten mit schlechter Datenqualität in Verbindung gebracht werden. Dazu gehören zumeist Dateneingabefehler, wie Tippfehler oder doppelte Dateneinträge, aber auch fehlende oder falsche Datenwerte.
Was ist eine ausreichend gute Datenqualität?
Natürlich gilt: je vollständiger, konsistenter und fehlerfreier Ihre Daten, desto besser. Dennoch ist es nahezu unmöglich, sicherzustellen, dass alle Daten die oben genannten Kriterien stets zu 100 % erfüllen. Tatsächlich müssen Ihre Daten auch gar nicht perfekt sein – stattdessen müssen sie vor allem die Anforderungen oder den Zweck erfüllen, zu welchem die Daten genutzt werden sollen.
Wie gut muss die Qualität der Daten für ein Data Science Projekt sein? Leider gibt es auf diese Frage keine allgemeingültige Antwort. Je nach Anwendung gibt es stets individuelle Aspekte, die sich auf die benötigte Datenqualität auswirken. Wie bereits angeführt, gehören dazu unter anderem der Zweck, zu welchem die Daten genutzt werden sollen. Das bedeutet also der Anwendungsfall sowie das gewünschte Modellierungsverfahren. Grundsätzlich sollten folgende Richtlinien beachtet werden:
1. Zweckorientiert: Die Datenqualität muss den spezifischen Geschäftsanforderungen und Verwendungszwecken genügen. Für einfache operative Prozesse reicht möglicherweise eine geringere Qualität als für kritische Analysen.
2. Risikobewertung: Je höher die potenziellen Risiken und Kosten bei fehlerhaften Daten sind, desto höher müssen die Qualitätsansprüche sein.
3. Stakeholder-Akzeptanz: Die Datenqualität sollte den Erwartungen und Mindestanforderungen aller Stakeholder und Datennutzer:innen entsprechen.
4. Ausgewogenheit: Es muss eine Balance zwischen akzeptablem Qualitätsniveau und vertretbarem Aufwand für Datenaufbereitung (Data Preparation) und Datenbereinigung gefunden werden.
5. Kontinuierliche Verbesserung: Die Qualitätsanforderungen sollten regelmäßig neu bewertet und schrittweise erhöht werden, wenn dies sinnvoll ist.
Letztlich gibt es keine pauschale "ausreichende" Datenqualität. Diese muss individuell unter Berücksichtigung von Nutzungsszenarien, Kosten, Risiken und der Weiterentwicklung des Unternehmens definiert werden. Ein ganzheitliches Datenqualitätsmanagement ist der Schlüssel.
Welche Fehler in der Datenqualität lassen sich korrigieren?
Es gibt verschiedene Arten von Fehlern in puncto Datenqualität, die je nach Schwere und Art unterschiedlich behandelt werden müssen. Sie ahnen es schon: Je schwieriger die Behandlung, desto teurer die Korrektur.
- Fehler, die mit relativ geringem Aufwand korrigiert werden können, z. B. Rechtschreibfehler oder doppelte Dateneingaben.
- Fehler, die mit erhöhtem Aufwand korrigiert werden können, z. B. Vermischung oder Abweichung von Formaten.
- Fehler, die hingegen nicht korrigiert werden können, z. B. ungültige Daten, fehlende oder veraltete Eingaben.
Um die Daten erfolgreich aufbereiten zu können, ist das Zusammenspiel von Data Scientists und den Fachbereichen notwendig, damit klar ist, welche Daten korrekt und welche zu korrigieren sind. Um sicherzustellen, dass jeder verstehen kann, was in den Daten steht, kann ein sogenanntes Data Dictionary helfen. Ein Data Dictionary ist ein wichtiges Werkzeug zur Überwachung und Verbesserung der Datenqualität. Es handelt sich um eine Sammlung von Metadaten, die Informationen über die Struktur, den Inhalt und die Verwendung von Daten enthalten.
Auch wenn sich manche Fehler also beheben lassen, besteht der bessere Ansatz immer darin, es erst gar nicht so weit kommen zu lassen. Unsere folgende Best Practice Checkliste hilft Ihnen dabei, Ihre Daten einem ersten Qualitätscheck zu unterziehen.
Datenqualitätsmanagement Best Practice Checkliste
Hier ist eine kurze Checkliste für Ihr Datenqualitätsmanagement.
Datenstrategie und Data Governance
- Definieren Sie klare Datenqualitätsziele und -metriken
- Benennen Sie Datenverantwortliche und erstellen Richtlinien
- Etablieren Sie Datenschutz- und Sicherheitsrichtlinien
Datenerfassung und Datenintegration
- Validieren Sie Daten bei der Eingabe durch Prüfregeln
- Beseitigen Sie Datensilos und integrieren Sie Datenquellen
- Nutzen Sie Master Data Management (MDM) für konsistente Stammdaten
Datenbereinigung und Datenberichtigung
- Implementieren Sie Deduplizierungs- und Datenabgleichsregeln
- Adressieren Sie fehlerhafte, inkonsistente und veraltete Daten
- Reichern Sie Daten mit externen Quellen an
Kontinuierliche Kontrolle
- Überwachen Sie die Datenqualität laufend
- Führen Sie regelmäßige Datenaudits durch
- Erstellen Sie Datenqualitätsberichte für das Management (& Stakeholder)
Mitarbeitende und Prozesse
- Bilden Sie Ihre Angestellten in Datenqualitätsmanagement aus
- Implementieren Sie Prozesse für Fehlermeldung und -behebung
- Automatisieren Sie Datenqualitätsroutinen nach Möglichkeit
Tooling und Technologie
- Setzen Sie dedizierte Data Quality Tools ein
- Integrieren Sie Datenqualitätsregeln in bestehende Systeme
- Nutzen Sie Data Governance und Funktionen für Metadaten
Verbesserungszyklus
- Analysieren und priorisieren Sie Datenqualitätsprobleme
- Optimieren Sie kontinuierlich Prozesse und Regeln
- Streben Sie Datenqualität als Kernkompetenz an
Fazit
Daten gelten mittlerweile als vierter Produktionsfaktor neben Boden, Kapital und Arbeit. Deswegen sind Daten somit als eine kritische Ressource zu betrachten, die es entsprechend zu managen gilt. Um eine hohe Datenqualität sicherzustellen, ist ein umfassendes Datenqualitätsmanagementsystem Pflicht. Datenqualität ist eine Managementaufgabe und fällt keinesfalls nur in den IT-Bereich. Das Thema Datenqualität ist die Grundlage der gesamten Datenstrategie. Dabei sind verschiedene Maßnahmen notwendig, die sowohl initiale, einmalige Maßnahmen, als auch kontinuierlich durchzuführende Tätigkeiten umfassen.
Denn Probleme in der Datenqualität haben nicht nur Auswirkungen auf den Erfolg eines Data Science Projekts, sondern sind mit weitreichenden Folgen für das Unternehmen insgesamt verbunden. Die gute Nachricht für Ihr Data Science Projekt lautet allerdings: Es braucht nicht den perfekten Datensatz. Und einige Fehler können im Rahmen der Datenaufbereitung von den Data Scientists behoben werden. Sparen Sie sich jedoch die Kosten und Kopfschmerzen durch ein solides Datenqualitätsmanagement und unsere Best Practice Checkliste.
FAQ
Was ist der wichtigste erste Schritt für bessere Datenqualität?
Der wichtigste erste Schritt ist die Bestandsaufnahme Ihrer aktuellen Datenlage. Führen Sie eine umfassende Analyse Ihrer vorhandenen Datenbestände durch und identifizieren Sie die kritischsten Qualitätsprobleme. Definieren Sie klare Datenqualitätsziele und benennen Sie Datenverantwortliche in Ihrem Unternehmen. Ohne diese Grundlage verpuffen alle weiteren Maßnahmen.
Wie kann ich sicherstellen, dass alle Daten korrekt und konsistent sind?
Eine hundertprozentige Korrektheit ist praktisch unmöglich, aber Sie können die Datenqualität systematisch verbessern:
- Implementieren Sie Validierungsregeln bei der Dateneingabe
- Etablieren Sie Master Data Management (MDM) für einheitliche Stammdaten
- Führen Sie regelmäßige Datenaudits durch
- Automatisieren Sie Qualitätsprüfungen wo möglich
- Schulen Sie Ihre Mitarbeitenden in korrekter Datenpflege
- Nutzen Sie Data Quality Tools für kontinuierliches Monitoring
Moderne KI-gestützte Lösungen können dabei helfen, Inkonsistenzen automatisch zu erkennen und zu korrigieren.
Welche Datenqualitätskriterien sind am wichtigsten?
Die fünf kritischsten Kriterien sind:
- Korrektheit - Stimmen die Daten mit der Realität überein?
- Vollständigkeit - Sind alle notwendigen Datenfelder gefüllt?
- Konsistenz - Sind die Daten in verschiedenen Systemen einheitlich?
- Aktualität - Spiegeln die Daten den aktuellen Zustand wider?
- Einheitlichkeit - Liegen die Daten in standardisierten Formaten vor?
Diese Kriterien sollten Sie priorisiert überwachen und kontinuierlich verbessern.
Kann ich Datenqualität auch bei großen Datenmengen (Big Data) sicherstellen?
Ja, auch bei Big Data ist hohe Datenqualität möglich:
- Nutzen Sie Cloud-basierte Lösungen für Skalierbarkeit
- Implementieren Sie automatisierte Qualitätsprüfungen in Echtzeit
- Verwenden Sie Machine Learning zur Fehlererkennung
- Etablieren Sie Data Lineage für Nachvollziehbarkeit
- Priorisieren Sie kritische Datensätze für intensive Prüfungen
Moderne KI-gestützte Plattformen können auch große Datenmengen effizient auf Qualität prüfen und dabei Muster erkennen, die manuell nicht erkennbar wären.